On IndyCar Ratings…
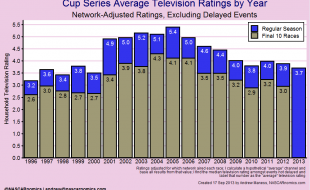
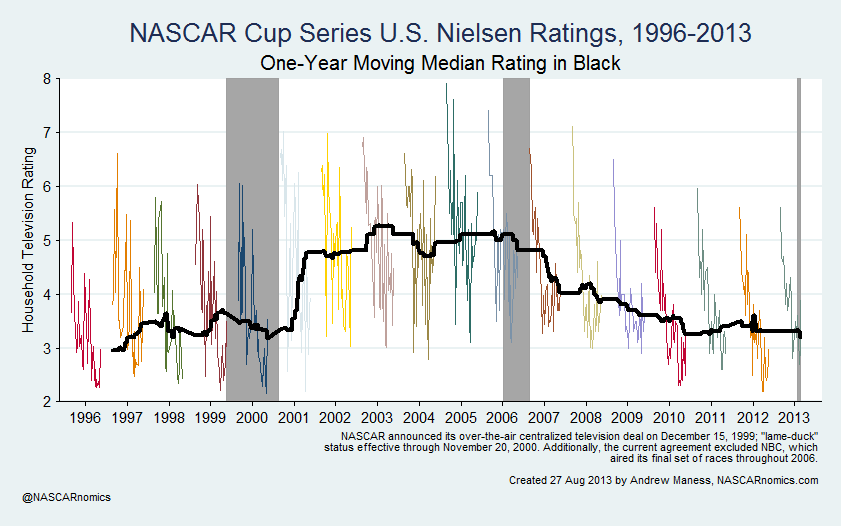
I recently shared a graph which charts the television ratings for INDYCAR’s IndyCar Series from 1996 through today. I plotted each race’s U.S. Nielsen rating and calculated the one-year moving average for the series’ household audience: The series’ popularity on television displays a downward trend for much of its history, …